Python中的类及元类metaclass
先来说说 Python 中最基本的类。
类也是对象
在 Python 中,类也是一种对象。在 Python 解释器执行的时候,就会创建一个对象。这个对象(类对象)拥有创建对象(实例对象)的能力。但是,它的本质仍然是一个对象所以,我们可以:
- 将它赋值给一个变量
- 拷贝它
- 为它增加属性
- 将它作为函数参数进行传递
Django 的 web 应用部署时采用 wsgi 协议与服务器对接,而这类服务器通常都是基于多线程的,也就是说每一个网络请求都会有一个对应的线程来进行处理。
Django 是走大而全的方向,注重的是高效开发,它最出名的是其全自动化的管理后台:只需要使用起ORM,做简单的对象定义,它就能自动生成数据库结构、以及全功能的管理后台。
Django 提供的方便,也意味着 Django 内置的 ORM 跟框架内的其他模块耦合程度高,应用程序必须使用 Django内置的ORM,否则就不能享受到框架内提供的种种基于其 ORM 的便利。
session功能
后台管理
ORM
Nginx 采用 Master-Worker 的多进程模型。
Nginx 启动后,Master 进程会去加载配置文件,建立好需要 Listen 的 Socket(Listenfd) 之后,然后 Fork 出多个 Worker 进程,Master 进程负责管理Worker 进程以及接收来自外接的信号,向各个 Worker 进程发送信号,监控 Worker 进程的运行状态,如有 Worker 异常退出,Master 进程会重新启动新的 Worker 进程。请求的处理是放在 Worker 进程中进行。
采用 Master-Worker 多进程的模式有诸多好处。
bug 导致 Worker 异常退出,Master 会启动新的 Worker 补充上,这样就不会对其他没有异常的服务造成影响,就不至于造成整个服务都无法访问。Worker 个数是确定的,一般 CPU 有多少核,就设置成多少,这样就不会造成无意义的进程切换及进程竞争开销。Nginx 是采用多路复用I/O模型(严谨点的话不能说是异步非阻塞I/O模型),所以它的并发量会比 Apache 高非常多,并且性能更好,更轻量。
Apache 中每个请求会独占一个工作线程,当并发数达到几千时,就同时有几千的线程在处理请求了。这对操作系统来说,是个不小的挑战,线程带来的内存占用非常大,线程的上下文切换带来的 CPU 开销很大,性能自然就上不去了,而且这些开销完全是没有意义的。阻塞的系统调用会导致 CPU 空闲,CPU 的利用率就会下降。
同步阻塞:线程会阻塞在那里等待返回,并让出 CPU
非阻塞:线程发现数据还没有可用的,就先直接先去做其他事情,定时自己来检查数据状态
异步非阻塞:线程发现数据没有可用的,然后把这个监控数据的任务交给操作系统,由操作系统来通知线程数据是否已经准备好。
有时候经常把异步非阻塞和非阻塞调用搞混,到底算不算异步,取决于进程向内核发起读取数据操作的时候,在内核把数据从内核态复制到用户态的这一时间内,进程是否处于阻塞状态。
Nginx 使用的是 epoll 模型,可以并发处理大量请求,但是同一时间能处理的请求当然也只有一个,只是在请求间不断地切换而已,切换是因为事件未准备好,而主动让出的。这里的切换是没有任何代价的,这跟 Apache 由于阻塞让出 CPU 是完全不同的。与多线程相比,Nginx 的处理机制有很大的优势,不需要创建线程,每个请求占用的内存也很少,没有上下文切换,不会造成竞争 CPU,事件处理也非常的轻量级。并发数再多也不会导致无谓的资源浪费。更多的连接只会造成更多的内存占用,在 1 G 的机器上,可容纳的连接数可达 10 万左右。
Linux I/O 模型
select、poll、epoll 请看我很早写的另一篇文章:
Linux I/O 模型之select、poll、epoll
着重讲了什么阻塞、非阻塞、异步、同步 及 select、poll、epoll 解析
当Nginx reload 发生的时候,比如执行 nginx -s reload
Master 进程收到信号后,会重新加载配置文件,然后向当前的 Worker 发出信号,并且告诉他们把当前手中的任务处理完你们就可以光荣退休了,不要再去竞争新的连接,然后 Master 会 Fork 出新的 Worker,此时新的 Worker 就是具备新的配置文件属性,因此就完成了热重启。
Nginx 负载均衡通过配置 upstream 模块来实现,内置了三种负载均衡策略。
s轮询(默认)/ 加权轮询
轮询:Nginx 根据请求次数,将每次请求均匀分配到每台服务器,如果每台服务器的性能都一样,那么在一定程度上是可以使用这种模式的。
1 | http { |
加权轮询:如果在 upstream 中的 server 参数最后面加上 weight=n ,就变成了加权轮询:
1 | upstream web1 { |
除了 weight 还支持其他的一些参数比如下面这条语句:
1 | upstream web1{ |
第一条server 语句的意思是 192.168.1.2:8080 这台服务器的权重是2,如果出现了 3 次请求失败,就等待 15 秒后再重新检测节点健康状态。
第二条 server 语句的意思是 192.168.1.10:8080 这台服务器作为备份机,所有服务器挂了之后才会生效。
即使请求转发到了不可用的节点,此次请求也不会丢失,因为 Nginx 会把此次请求转发到另一个可用节点,如果节点全部不可用,Nginx 会返回最后一个节点返回的信息响应给客户端。
请求失败的定义:与服务端建立连接、向服务端发送请求或者解析服务端响应头时,发生异常或超时被认为是通信失败,服务端返回的响应为空或不合法会被认为是通信失败,如果配置了 http_500、http_502、http_503、http_504 和 http_429,服务端返回这些状态码会被认为是通信失败,服务端返回 http_403、 http_404 永远不会被认为通信失败。
upstream 存在一些问题:
backup: 备份机,所有服务器挂了之后才会生效
max_fails: 默认为1,某台 Server 允许请求失败的次数,超过最大次数后,在 fail_timeout 时间内,新的请求将不会分配给这台机器。如果设置为0,Nginx 会将这台 Server 置为永久无效状态,然后将请求发送到其他 handler 来处理这次的错误请求。
fail_timeout: 默认10秒。某台Server达到 max_fails 次失败请求后,在fail_timeout期间内,Nginx会认为这台Server暂时不可用,不会将请求分配给它。
max_conns: 限制分配给某台 Server 当前正在处理的最大连接数量,超过这个数量,将不会分配新的连接给它。默认为0,表示不限制。1.5.9 以后才有这个参数
resolve: 将 server 指令配置的域名,指定域名解析服务器。需要在 http 模块下配置 resolver 指令,指定域名解析服务。
1 | http { |
最少连接
将请求分配给连接数最少的服务器。 Nginx 会统计哪些服务器的连接数最少
IP Hash
绑定处理请求的服务器。第一次请求时,根据客户端的 IP 算出一个 HASH 值,将请求分配到集群中的某一台服务器上。后面该客户端的所有请求,都将通过 HASH 算法,找到之前处理这台客户端请求的服务器,然后将请求交给它来处理。
URL_Hash
在1.7.2版本之后,加入了 url_hash 策略,按照请求 url 的 hash 结果来分配请求,使每个 url 定向到同一个后端服务器,服务器做缓存时比较有效。
1 | upstream web1 { |
除了以上三种是官方自带的负载均衡策略,还有第三方的,比较常用的有一下几个
根据服务器的响应时间来分配请求,响应时间短的优先分配,即负载压力小的优先会分配。
使用第三方模块时,我们需要在编译 Nginx 源码时,将其添加到 Nginx 模块中,具体方法可以查看第三方模块 README。
nginx_upstream_check_module
这个模块时由淘宝开发,后端服务器健康检查状态都存在于共享内存中,共享内存的大小需要根据服务器数量进行设置
1 | http { |
1 | upstream xx{ |
请求到 Nginx 后, Nginx 帮你去请求你的目标地址,目标地址把请求响应发送给 Nginx,Nginx 再重新组装包返回给客户端。这样可以隐藏客户端的IP地址。
请求到 Nginx 后, Nginx 将请求分发给后端服务器进行处理,后端服务器再将响应返回给Nginx,再由 Nginx 将响应做一些修改后,返回给客户端。在这个过程中, 后端真实服务器地址对客户端是不可见的。
前些日子,面试官问我 HTTP 和 HTTPS 的区别的时候?
我总是说 HTTPS 就是在传输层和应用层之间加了一个基于TLS的加密协议。

后来,反复审视自己的问题。觉得了解一个东西不要太表面。他也没深问,我也没往下说。
我自己是写了一个线上的 WEB 应用,偶尔就会接到反馈说我的网页怎么点击按钮没反应。
然后我反复纠结是否是我 js 代码写的有问题,无论怎么改,都会出现十次有两三次的现象,按钮无效,无法提交表单。
细心观察发现,那些无法执行的时候,页面上总是有些乱七八糟的广告,要么就是有个移动流量的圆球,要么就是什么吸引眼球的点击网页。
今天有一个文件,每次处理之后,发布之前总需要替换一些东西,本来想着写个脚本,但是后来又发现没必要,一行sed命令就可以解决的事情,于是写了写sed
然后发现 sed 的对于一些正则表达式的支持在 Mac 上面不一样。
事情是这样的,我处理完文件之后,把它处理的结果重定向到文件里面,然后我打开文件,发现,其实它是没有改变的,但是如果输出到 stdout 就是命令行,它是修改了的,然后就研究了一会。
在 Mac 上的 sed 正则表达式问题, 在 Linux 上面工作正常
我的解决方法是将原本的
➜ sed -i 's/\(^\s*!\[image.*\)\.\.\(.*\)/\1\2/g' tmp.md > a.md
\s 替换成空格
➜ sed -e 's/\(^ *!\[image.*\)\.\.\(.*\)/\1\2/g' tmp.md > a.md
然后就可以了。
很多概念就是在不断讨论中,不断查询中,不断修正。
用户空间和内核空间
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为 4GB(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对 Linux 操作系统而言,将最高的 1GB 字节(从虚拟地址 0xC0000000 到 0xFFFFFFFF ),供内核使用,称为内核空间,而将较低的 3GB 字节(从虚拟地址 0x00000000 到0xBFFFFFFF ),供各个进程使用,称为用户空间。
每个进程的 4GB 进程空间中,最高 1GB 都是一样的,即内核空间。只有剩余的 3GB 才归进程自己使用。
换句话说就是、最高 1GB 的内核空间是被所有进程共享的!
如图:
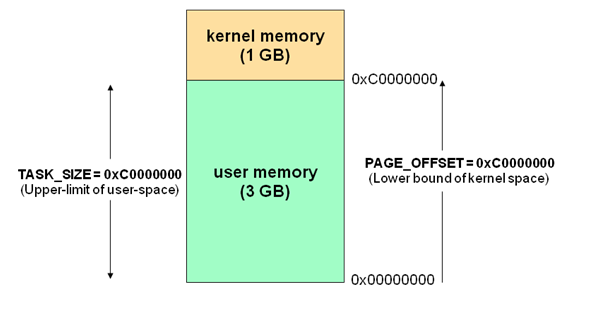
详情请参考: Linux 内核空间与用户空间
Redis 是一个开源的内存中的数据存储系统, 可以用作 : 数据库、 缓存和消息中间件。
常见的数据类型: String (字符串), Hash(散列),List(列表),Set(集合),有序集合(Sorted Set或者ZSet)与范围查询, Bitmaps, Hyperloglogs 和地理空间(Geospatial)索引半径查询。
数据库的工作模式按存储方式可以分为: 硬盘数据库和内存数据库。 Redis 将数据储存在内存里面,读写数据的时候都不会受到磁盘 I/O 速度的限制,所以速度极快。
磁盘数据库每次加载数据会存在 I/O速度的限制
| I/O 类型 | 花费的 CPU 时钟周期 |
|---|---|
| CUP一级缓存 | 3 |
| CPU二级缓存 | 14 |
| 内存 | 250 |
| 硬盘 | 41000000 |
| 网络 | 240000000 |
Redis 采用的是基于内存的单进程单线程模型的 KV 数据库, 由 C 语言编写,官方提供的数据是可以达到 10万+ 的 QPS(每秒内查询次数)。 这个数据不比采用单进程多线程同样基于内存的 KV 数据库 Memcached 差,官方给的基准程序测试:
设有n个正整数,将他们连接成一排,组成一个最大的多位整数。
如:n=3时,3个整数13,312,343,连成的最大整数为34331213。
如:n=4时,4个整数7,13,4,246连接成的最大整数为7424613。
输入
2
12 123
输出
12312
代码:
1 | import sys |
主要是实现一个比较器来决定每个数据的排序顺序。