可变对象与不可变对象
关于“可变对象”和“不可变对象”的区别。可变对象维护的数据在对象创建后还能再变化,比如一个 list 被创建后,可以向其中添加或者删除元素,这些操作都会改变其维护的数据;而不可变对象所维护的数据在对象创建之后就不能再改变了,比如 Python 中的 string 和 tuple,它们都不支持添加或者删除的操作。
PyStringObject 与 PyString_Type
PyStringObject 是对字符串对象的实现。PyStringObject 是一个拥有可变长度内存的对象,因为表示 “Hi” 和 “Python” 的两个不同的 PyStringObject 对象,其内部所需的保存字符串内容的内存空间显然是不一样的。同时,PyStringObject 对象又是一个不可变对象。就是创建后,该对象内部维护的字符串就不能再改变了。这一点特性使得 PyStringObject 对象可作为 dict 的键值,但同时也使得一些字符串操作的效率大大降低,比如多个字符串的连接操作。
PyStringObject的定义如下:
1 | [stringobject.h] |
PyStringObject 的头部实际上是一个 PyObject_VAR_HEAD,其中有一个 ob_size 变量保存着对象中维护的可变长度内存的大小。虽然在 PyStringObject 的定义中,ob_sval 是一个字符的字符数组。但是 ob_sval 实际上是作为一个字符指针指向一段内存,这段内存保存着这个字符串对象所维护的实际字符串,显然,这段内存不会只是一个字节。而这段内存的时间长度(字节),正式由 ob_size 来维护的,这个机制是 Python 中所有变长对象的实现机制。比如“Python”这个字符串对象里的 ob_size 的值为6。
同 C 中的字符串一样, PyStringObject 内部维护的字符串在末尾必须以 ‘\0’ 结尾,但是由于实际长度是由 ob_size 维护的,所以 PyStringObject 表示的字符串对象中间是可能出现 ‘\0’ 。
ob_shash 变量的作用是缓存该对象的 hash 值,这样可以避免每一次都重新计算该字符串对象的 hash 值。如果一个对象还没有被计算过 hash 值,那么 ob_shash 的初始值就是 -1 。这个 hash 在 dict 里会发挥巨大的作用。
ob_sstate 变量标记了该对象是否已经过 intern 机制处理。预存 字符串的 hash 值和 intern 机制将 Python 虚拟机的执行效率提升了 20%。

PyStringObject 对象的内存布局
Unicode的四种形式
在Python3中,一个unicode字符串有四种形式:
- compact ascii
- compact
- legacy string, not ready
- legacy string ,ready
compact的意思是,假如一个字符串对象是compact的模式,它将只使用一个内存块来存储内容,也就是说,在内存中字符是紧紧跟在结构体后面的。对于non-compact的对象来说,也就是PyUnicodeObject,Python使用一个内存块来保存PyUnicodeObject结构体,另一个内存块来保存字符。
对于ASCII-only的字符串,Python使用PyUnicode_New来创建,并将其保存在PyASCIIObject结构体中。只要它是通过UTF-8来解码的,utf-8字符串就是数据本身,也就是说两者等价。
legacy string 是通过PyUnicodeObject来保存的。
Intern 机制
指的就是在创建一个新的字符串对象时,如果已经有了和它的值相同的字符串对象,那么就直接返回那个对象的引用,而不返回新创建的字符串对象。Python 在哪里寻找呢?事实上,Python 维护着一个键值对类型的结构 interned,键就是字符串的值。但这个 intern 机制并非对于所有的字符串对象都适用,简单来说对于那些符合 Python 标识符命名原则的字符串,也就是只包括字母数字下划线的字符串,Python 会对它们使用 intern 机制。在标准库中,有一个函数可以让我们对一个字符串强制实行这个机制—— sys.intern()。
所谓的 intern 机制的关键,就是在系统中一个(key, value)映射关系的集合,集合的名称叫做 interned。在这个集合中,记录着被 intern 机制处理过的 PyStringObject 对象。
字符串缓冲池
在 Python 的整数对象体系中,小整数的缓冲池是在 Python 初始化时被创建的,而字符串对象体系中的字符串缓冲池则是以静态变量的形式存在着的。在 Python 初始化完成之后,缓冲池中的所有 PyString 指针都为空。
当我们在创建一个 PyStringObject 对象时,无论是通过调用 PyString_FromString 还是通过调用 PyString_FromStringAndSize,如果字符串实际上是一个字符,则会进行如下操作:
1 | [stringobject.c] |
先对所创键的字符串对象进行 intern 操作,再将 intern 的结果缓存到字符缓冲池 characters 中。如图:
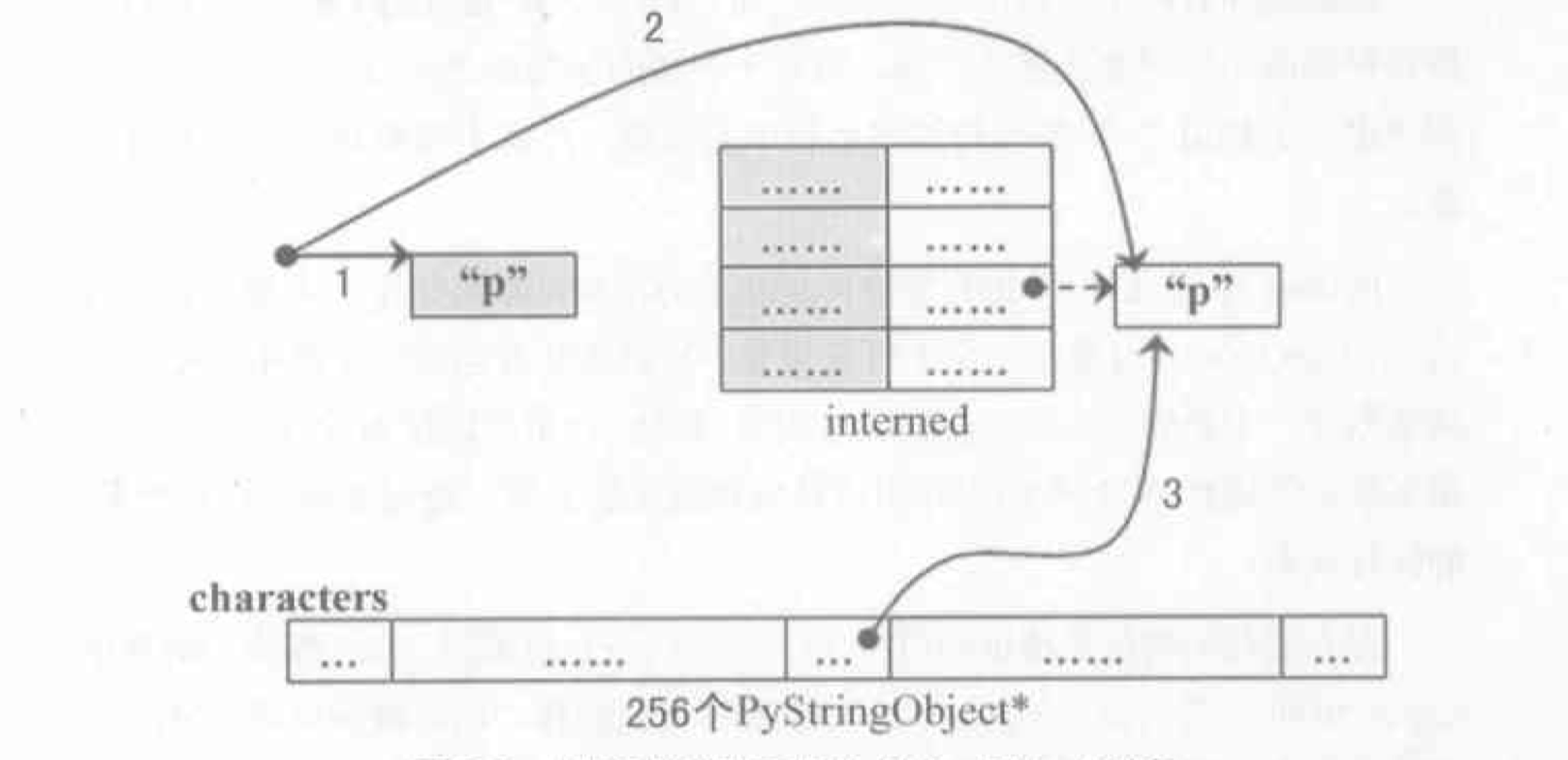
- 创建 PyStringObject 对象
<string p> - 对对象
<string p>进行 intern 操作 - 将对象
<string p>缓存至字符缓存池中。
在创建一个 PyStringObject 时,会首先检查所要创建的是否是一个字符对象,然后检查字符缓冲池中是否已经有了这个字符的字符对象的缓冲,如果有,则直接返回这个缓冲的对象即可。
PyStringObject 效率问题
假如现在有两个字符串“Hello” 和 “World”,在 Python 中可以使用 “+” 操作符将两个字符串连接在一起,得到一个新的字符串 “HelloWorld”。但是这样做,效率极其低下,如果有 N 个要连接,那么必须要进行 N-1 次的内存申请及内存搬运工作。这将严重影响 Python 的执行效率。
官方推荐的做法是通过 join 操作来对存储在 list 或 tuple 中的一组 PyStringObject 对象进行连接操作,这样只需要分配一次内存,执行效率大大提高。