Tornado 对比 Django
Django 的 web 应用部署时采用 wsgi 协议与服务器对接,而这类服务器通常都是基于多线程的,也就是说每一个网络请求都会有一个对应的线程来进行处理。
Django 是走大而全的方向,注重的是高效开发,它最出名的是其全自动化的管理后台:只需要使用起ORM,做简单的对象定义,它就能自动生成数据库结构、以及全功能的管理后台。
Django 提供的方便,也意味着 Django 内置的 ORM 跟框架内的其他模块耦合程度高,应用程序必须使用 Django内置的ORM,否则就不能享受到框架内提供的种种基于其 ORM 的便利。
session功能
后台管理
ORM
Tornado走的是少而精的方向,注重的是性能优越,它最出名的是异步非阻塞的设计方式。
- HTTP服务器
- 异步编程
- WebSockets
Tornado 应该运行在类Unix平台,在线上部署时为了最佳的性能和扩展性,仅推荐 Linux 和 BSD(因为充分利用Linux的 epoll 工具和 BSD 的 kqueue 工具,是 Tornado 不依靠多进程/多线程而达到高性能的原因)。
对于Mac OS X,虽然也是衍生自 BSD 并且支持 kqueue,但是其网络性能通常不太给力,因此仅推荐用于开发。
对于 Windows,Tornado 官方没有提供配置支持,但是也可以运行起来,不过仅推荐在开发中使用。
在大量的HTTP持久连接存在的情况下
用户量大,高并发
如抢购、春节抢火车票、双十一淘宝等等
使用同一个 TCP 连接来发送和接受多个 HTTP 请求/应答,而不是为每一个新的请求/应答打开新的连接。
对于 HTTP 1.0 ,可以在请求的包头 (Header) 中添加 Connection: Keep-Alive
对于 HTTP 1.1,所有的连接默认都是持久连接。
对于这两种场景,多线程的服务器很难应付。
底层模型 select、poll、epoll 对比,都是非阻塞 I/O,epoll 的优势在于可以高效处理存在很多并不活跃的连接。如果都是比较活跃的连接,epoll 优势并没有特别明显,因为都是需要处理的。具体研究可以看selct、poll、epoll的研究
C10K问题
对于前文提出的这种高并发问题,我们通常用C10K这一概念来描述。C10K—— Concurrently handling ten thousand connections,即并发10000个连接。对于单台服务器而言,根本无法承担,而采用多台服务器分布式又意味着高昂的成本。如何解决C10K问题?
Tornado 的一些特点
作为 Web 框架,是一个轻量级的 Web 框架,类似于另一个 Python web 框架 Web.py,其拥有异步非阻塞 I/O 的处理方式。
作为 Web 服务器,Tornado 有较为出色的抗负载能力,官方用 nginx 反向代理的方式部署 Tornado 和其它Python web 应用框架进行对比,结果最大浏览量超过第二名近40%。
性能: Tornado 有着优异的性能。它试图解决 C10k 问题,即处理大于或等于一万的并发,下表是和一些其他Web 框架与服务器的对比:

tornado 分为框架 和 服务器,推荐一起使用它的框架和服务器,否则就无法很好的发挥异步非阻塞的优势。
对于 Tornado 的研究
首先,一个简单的 Tornado 代码:
1 | # coding:utf-8 |
保存为 hello.py 文件,执行
# python hello.py
打开浏览器,输入网址127.0.0.1:8000(或localhost:8000),查看效果:
其中,其他的我们先不关心,我们先关心其中的 ioloop:
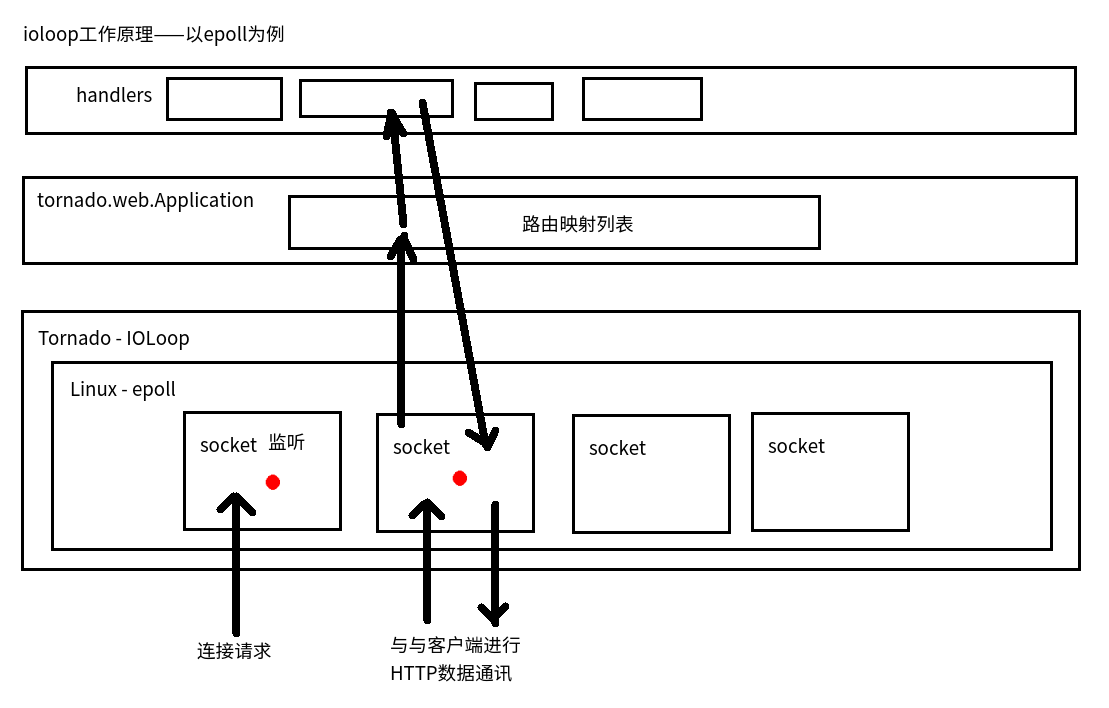
tornado的核心io循环模块,封装了Linux的epoll和BSD的kqueue,tornado高性能的基石。 以Linux的epoll为例,其原理如下图:
IOLoop.current()
返回当前线程的IOLoop实例。
IOLoop.start()
启动IOLoop实例的I/O循环,同时服务器监听被打开。
Tornado WEB 应用编写思路
创建web应用实例对象,第一个初始化参数为路由映射列表。
定义实现路由映射列表中的handler类。
创建服务器实例,绑定服务器端口。
启动当前线程的IOLoop。
Tornado使用了协程
Tornado 编程中很多使用 yield 关键字
协程是什么?
我们在平常编程中,更习惯使用的是子例程(subroutine),通俗的叫法是函数,或者过程。子例程,往往只有一个入口(函数调用,实参通过传给形参开始执行),一个出口(函数return,执行完毕,或者引发异常,将控制权转移给调用者)。但协程是子例程基础上,一种更加宽泛定义的计算机程序模块(子例程可以看做协程的特例),它可以有多个入口点,允许从一个入口点,执行到下一个入口点之前暂停,保存执行状态,等到合适的时机恢复执行状态,从下一个入口点重新开始执行,这也是协程应该具有的能力。
协程是一组序列化的子过程,然后用户能像指挥家一样调度交叉执行
它并不会参与 CPU 时间调度,并没有均衡分配到时间。
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,所以上下文的切换非常快。
曾被问到 tornado 里的 yield 和 python 本身的 yield 一样吗?
生成器和 yield 的语义
什么是生成器?
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
这是一个列表生成式:
L = [ x*2 for x in range(5)]
这是一个生成器:
G = ( x*2 for x in range(5))
要创建一个生成器,有很多种方法。第一种方法很简单,只要把一个列表生成式的 [ ] 改成 ( )
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的 for 循环无法实现的时候,还可以用函数来实现。
1 | # 用函数实现一个生成器,需要使用到 yield |
生成器是这样一个函数,它记住上一次返回时在函数体中的位置。对生成器函数的第二次(或第 n 次)调用跳转至该函数中间,而上次调用的所有局部变量都保持不变。
生成器不仅“记住”了它数据状态;生成器还“记住”了它在流控制构造(在命令式编程中,这种构造不只是数据值)中的位置。
生成器的特点:
- 节约内存
- 迭代到下一次的调用时,所使用的参数都是第一次所保留下的,即是说,在整个所有函数调用的参数都是第一次所调用时保留的,而不是新创建的。
Tornado官方文档阅读
主要记录一下,在阅读文档时候,遇到的一些问题:
一个简单的同步函数:
1 | from tornado.httpclient import HTTPClient |
把上面的例子用回调参数重写的异步函数:
1 | from tornado.httpclient import AsyncHTTPClient |
协程库 (
tornado.gen) 允许异步代码写的更直接而不用链式回调的方式。
使用 Future 代替回调:
1 | from tornado.concurrent import Future |
Future 版本明显更加复杂,但是 Futures 却是Tornado中推荐的写法 因为它有两个主要的优势.首先是错误处理更加一致,因为 Future.result 方法可以简单的抛出异常(相较于常见的回调函数接口特别指定错误处理), 而且 Futures 很适合和协程一起使用.协程会在后面深入讨论.这里是上 面例子的协程版本,和最初的同步版本很像:
1 | from tornado import gen |
raise gen.Return(response.body) 声明是在Python 2 (and 3.2)下人为 执行的, 因为在其中生成器不允许返回值.为了克服这个问题,Tornado的协程 抛出一种特殊的叫 Return 的异常. 协程捕获这个异常并把它作为返回值. 在Python 3.3和更高版本,使用 return response.body 有相同的结果.
Future
Future 类重要成员函数:
def done(self):
Future的_result成员是否被设置
def result(self, timeout=None):
获取Future对象的结果
def add_done_callback(self, fn):
添加一个回调函数fn给Future对象。如果这个Future对象已经done,则直接执行fn,否则将fn加入到Future类的一个成员列表中保存。
def _set_done(self):
一个内部函数,主要是遍历列表,逐个调用列表中的callback函数,也就是前面add_done_calback加如来的。
def set_result(self, result):
给Future对象设置result,并且调用_set_done。也就是说,当Future对象获得result后,所有add_done_callback加入的回调函数就会执行。
如果看过 select或者poll、或者epoll 的实现方式,及源码,理解也不难,Tornado 不过是把非阻塞I/O 模型进行了封装。
Future 封装了异步操作的结果。Tornado使用它,最终希望它被 set_result ,并且调用一些回调函数。Future对象实际是 coroutine(协程) 函数装饰器和 IOLoop 的沟通使者,有着非常重要的作用。
总的来说,就是通过 IOLoop 进行不断的循环,通过 Future 来设置状态,就可以达到异步的效果。
Tornado源码必须要读的几个核心文件 这个网站有时候需要多刷新几次
Tornado 的数据库
tornado 的数据库,官方并默认并不是异步的,如果数据库查询太慢,那么将会拖慢整体性能。
但是,如果数据库查询都很慢,那么重点也不是放在 Tornado 优化上面了,而是想象如何去优化数据库的性能。
也可以通过一些方法,把数据库改成异步调用。