Redis 简介
Redis 是一个开源的内存中的数据存储系统, 可以用作 : 数据库、 缓存和消息中间件。
常见的数据类型: String (字符串), Hash(散列),List(列表),Set(集合),有序集合(Sorted Set或者ZSet)与范围查询, Bitmaps, Hyperloglogs 和地理空间(Geospatial)索引半径查询。
数据库的工作模式按存储方式可以分为: 硬盘数据库和内存数据库。 Redis 将数据储存在内存里面,读写数据的时候都不会受到磁盘 I/O 速度的限制,所以速度极快。
磁盘数据库每次加载数据会存在 I/O速度的限制
- 不同 I/O 类型及其对 CPU 的开销
| I/O 类型 | 花费的 CPU 时钟周期 |
|---|---|
| CUP一级缓存 | 3 |
| CPU二级缓存 | 14 |
| 内存 | 250 |
| 硬盘 | 41000000 |
| 网络 | 240000000 |
Redis 采用的是基于内存的单进程单线程模型的 KV 数据库, 由 C 语言编写,官方提供的数据是可以达到 10万+ 的 QPS(每秒内查询次数)。 这个数据不比采用单进程多线程同样基于内存的 KV 数据库 Memcached 差,官方给的基准程序测试:
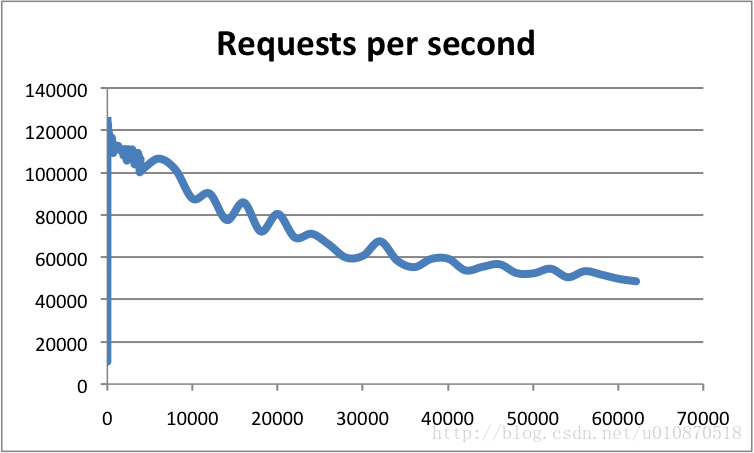
横轴是连接数,纵轴是 QPS 。
为什么那么快
完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap, HashMap的优势就是查找和操作的时间复杂度都是O(1)。
数据结构简单,对数据操作也简单, Redis 中的数据结构是专门进行设计的。
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现的死锁导致的性能消耗。
使用多路 I/O 复用模型, 非阻塞 IO。可以让单个线程高效处理多个连接请求,且 Reids 在内存中操作数据非常快,内存内的操作不会是 Redis 的性能瓶颈。
底层模型不同,它们之间底层实现方式以及与客户端之间通信协议不一样,Redis直接自己构建了VM 机制,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
为什么 Redis 是单线程的
首先 Redis 基于内存操作, CPU 不是 Redis 的瓶颈
Redis 的瓶颈有可能是机器内存的大小或者网络带宽
既然单线程容易实现,而且 CPU 不会成为瓶颈,那就采用单线程方案了,毕竟多线程会有很多麻烦需要去解决。
单线程情况下已经很快了,就没有必要在使用多线程。但是单线程无法发挥多核 CPU 性能,我们可以在单机多开几个 Redis 实例来完善。
单线程指的是处理网络请求只有一个线程,一个 Redis server 运行的时候肯定是布置一个线程的。
Redis 注意
因为 Redis 是单线程-多路复用I/O模型,这种模型避免了多线程的很多问题,如死锁。
但是,只有一个线程,如果遇到非常消耗 CPU 的命令,那么 Redis 的并发量将会下降。为了避免这个问题,可以在同一多核服务器中,启动多个实例,组成 master-master 或者 master-salve 的形式,耗时命令可以放到 slave 进行。
常见的数据库模型:
- 单进程多线程模型: MySQL 、 Memcached、 Oracle (windows版本)
- 多进程模型: Oracle (Linux 版本)
- Nginx 有两类进程, 一类为 Master进程(管理进程),另一类为 Worker 进程(实际工作进程)启动方式有两种:
- 单进程启动:此时系统中仅有一个进程,该进程既充当 Master , 也充当 Worker 。
- 多进程启动:此时系统有且仅有一个 Master 进程,至少有一个 Worker 进程。
- Master 进程主要进行一些全局性的初始化工作和管理 Worker 工作;事件是在 Worker 中进行的。